

Ça fait des décennies qu’on construit nos applications autour d’un ORM. Dans les faits, c’est bien souvent un point de douleur dans nos codes legacy. Nous avons vu dans un premier article en quoi l’ORM participe au legacy, puis comment un retour au SQL, en tirant parti de la lib jOOQ, constitue une amélioration de la situation. Mais doit-on s’arrêter là ? Comment aller plus loin pour éviter de reproduire les mêmes travers ? C’est ce que nous essaierons de voir dans le cadre de ce deuxième article.
Bien migrer vers jOOQ
L’intégration de jOOQ est simple : des plugins Maven et Gradle, notamment, automatisent la génération des sources dans le cadre du build par simple configuration. La documentation officielle propose un guide en plusieurs étapes. Pour une application Spring Boot, l’intégration est encore plus simple (cf. documentation Spring Boot).
Pas besoin de big bang
Il est techniquement possible de faire coexister JPA et jOOQ dans une même application. Ce n’est pas souhaitable de manière durable, mais c’est un moyen de procéder à des migrations de manière graduelle, pour éviter l’effet big bang.
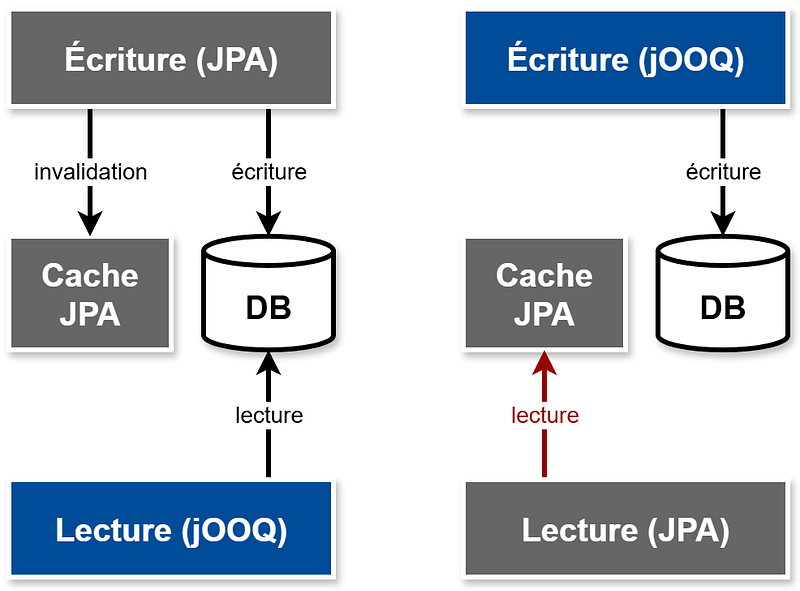
Attention néanmoins à bien faire les choses dans l’ordre. La définition d’un modèle objet unique pour l’ORM implique la récupération d’objets par grappes pour les listes et donc la multiplication des requêtes SQL. Afin d’assurer de bonnes performances, JPA intègre donc un système de cache, avec un cache de session, obligatoire, et un cache de second niveau, facultatif.
Pour une table donnée, la migration de la lecture doit donc être priorisée sur celle de l’écriture. En effet, la lecture avec JPA utilise le cache qui ne sera pas tenu à jour par les écritures de jOOQ. À l’inverse, la lecture avec jOOQ utilisera toujours la base de données directement (cf. First-level cache and second-level cache).
Des contraintes liées aux problèmes de conception
Les problèmes de conception liés aux contraintes de JPA s’avèrent bien souvent des freins dans une migration vers jOOQ. Notamment, quand une même table est utilisée dans de multiples objets de notre modèle, elle est susceptible d’être mise à jour lors de l’écriture de tous ces objets, ce qui signifie qu’on devra attendre d’avoir migré la lecture pour tous ces objets avant de commencer à migrer l’écriture pour l’un d’entre eux.
On peut faire le choix d’accepter ces contraintes pour réaliser une migration a minima, avec aussi peu d’impact sur l’existant que possible. Dans ce cas, on sait qu’on conservera un grand nombre de problèmes de conception liés à JPA à l’issue de la migration. Considérer le travail comme terminé à ce stade serait une erreur.
À l’inverse, on peut faire le choix de profiter de l’occasion pour assainir la situation en commençant par s’occuper de ces problèmes de conception, ce qui simplifiera considérablement la migration par la suite.
Make the change easy, then make the easy change.
Kent Beck
Un modèle à démêler
On l’a mentionné dans le premier article, avoir une représentation unique de nos données pour tous nos cas d’usage est un problème. Et sans lazy loading, charger une grappe d’objets trop conséquente en mémoire à chaque accès devient inenvisageable, quand ce n’est pas tout simplement impossible du fait des dépendances cycliques.
Alors comment casser ces dépendances cycliques et plus généralement diminuer le couplage entre les objets manipulés pour aboutir à des unités autonomes ?
Remplacer la composition par des références
Une première option peut être de remplacer la composition d’objets par des références. Prenons par exemple le lien de la classe Author vers la classe Book :
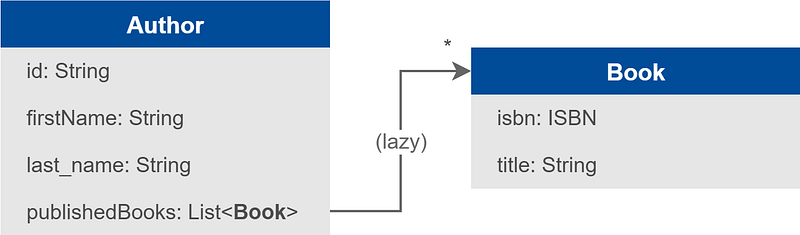
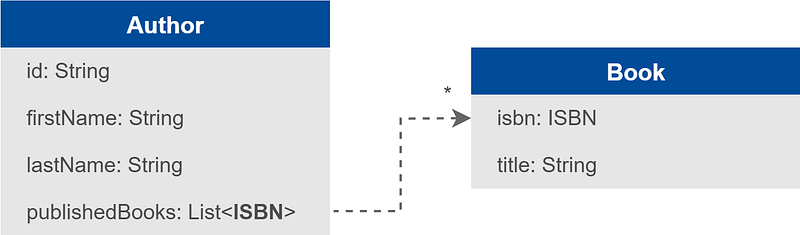
Quand on charge une instance de Author, on charge la liste des ISBNs de ses livres et non plus les instances de Book. Si le détail des livres s’avère nécessaire, ça donnera lieu à des requêtes supplémentaires. C’était déjà le cas précédemment, dans le fameux problème N+1. Mais ce qui pouvait être auparavant considéré comme un problème, une surprise, quelque chose de mal contrôlé, est désormais clair, explicite, délibéré.
Faire émerger un concept pour la relation
Une deuxième option est de faire émerger des concepts métier. On peut par exemple appliquer cette solution à la relation bidirectionnelle entre les classes Book et Library :


On fait ici émerger le concept de catalogue de bibliothèque. La séparation de ce concept a du sens : le catalogue n’évolue pas au même rythme que les autres données de la bibliothèque, et quand on charge une liste des bibliothèques, leurs catalogues ne nous sont pas forcément utiles. Dans les cas où ils le sont, ça donnera lieu à 1 requête SQL supplémentaire, ce qui est tout à fait acceptable. Autre effet bénéfique : comme le concept est isolé, il nous sera plus facile de le faire évoluer (ce qui sera vraisemblablement nécessaire pour gérer les quantités) sans risque pour ce qu’il y a à côté.
Dénormaliser la donnée
Une troisième option est de dénormaliser. On peut l’envisager par exemple pour le lien de la classe Book vers la classe Author :
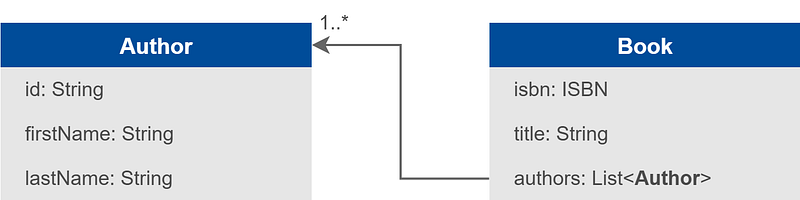

Il s’agit de dupliquer la donnée, ou tout du moins la partie qui est pertinente pour ce contexte précis. En l’occurrence, on prend un instantané des champs de Author dans une instance de AuthorInfo au moment de la création du livre, ce qui donne lieu à l’introduction d’une nouvelle table ou d’un champ structuré (par exemple en JSON) dans la base de données.
En contrepartie, en cas de modification des données d’un·e auteur·ice, cela peut aboutir à des incohérences. Il est donc nécessaire de considérer de telles divergences comme acceptables. Même s’il serait techniquement possible de gérer la propagation des modifications, la complexité induite rendrait la dénormalisation contre-productive. Dans notre cas, c’est acceptable : les informations de l’auteur·ice sont des données statiques et si, extraordinairement, elles venaient à changer, les incohérences ne prêteraient pas à conséquence. Au contraire, on pourrait même considérer qu’il est préférable de les conserver, dans la mesure où, en cas de changement de nom d’un·e auteur·ice, on peut souhaiter continuer à afficher le nom qui est effectivement écrit sur la couverture.
Aller plus loin avec le DDD
Globalement, il est crucial d’avoir un point d’entrée unique pour les écritures sur une table donnée. En cela, on rejoint la notion d’agrégat du Domain-Driven Design. La question de la définition des agrégats est loin d’être triviale : il n’y a jamais de bonne réponse, juste beaucoup de facteurs à peser pour aboutir à un code maintenable. Pour aller plus loin sur cette question, vous pouvez vous référer à la série d’articles Effective Aggregate Design de Vaughn Vernon.
Impact sur une architecture en couches
L’impact de jOOQ sur une architecture en couches dépend de l’étanchéité de celle-ci.
Quand les entités JPA sont de simples DTO
Les entités JPA peuvent être définies comme des DTO, au sens où il s’agit d’objets définis spécifiquement pour transporter des données entre 2 couches de votre architecture (dans notre cas, la couche d’accès à la base de données et la base à proprement parler).

Si vous êtes dans ce cas, la migration est triviale : le DTO est tout simplement remplacé par le code généré par jOOQ.
- Définissez le mapping entre les objets générés par jOOQ et le modèle de données de la couche en amont.
- Remplacez tous les usages de l’entité JPA par jOOQ.
- Supprimez l’entité JPA.
Avec des entités JPA “multifonctions”
Il est également possible de définir des entités JPA en ajoutant simplement des annotations à des objets qui ont déjà d’autres responsabilités dans votre code. Le défaut de cette approche, outre le brouillage des responsabilités, tient dans le fait que le modèle est contaminé par de la complexité accidentelle, comme on l’a décrit dans le premier article.
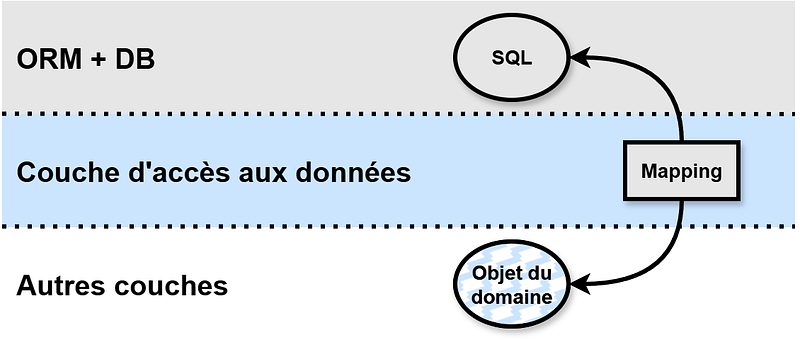
Dans ce cas de figure, on souhaite donc extraire la responsabilité de mapping avec la DB de l’entité JPA préexistante.
- Définissez le mapping entre les objets générés par jOOQ et l’entité JPA.
- Remplacez tous les usages de l’entité JPA par jOOQ.
- Supprimez les annotations JPA, désormais obsolètes, de l’objet et profitez en pour le supprimer.
On pourrait considérer l’idée d’utiliser le code généré par jOOQ pour remplacer l’entité JPA préexistante partout ; ce n’est pas préconisé, dans la mesure où il s’agirait d’une augmentation du couplage de tout votre code avec le modèle de la base de données. Alors qu’il peut exister des stratégies pour absorber des modifications du modèle de la base dans une entité JPA (l’annotation Embedded, par exemple), avec le code généré par jOOQ, toute modification du modèle de la base de données viendrait casser votre code.
Conclusion
Passer à jOOQ, ce n’est pas seulement un assainissement de votre legacy en soi, mais également une occasion de reprendre le contrôle sur votre code. Le fait de devoir écrire explicitement chaque requête que vous voulez exécuter, sans le biais qu’apporte le paradigme objet, vous force à vous interroger sur la conception de votre logiciel. Bien entendu, ça n’empêche pas tous les problèmes, mais ça en résout certains et ça rend surtout les autres bien visibles, rendant par là même votre code plus facile à maintenir.
Cependant, passer le pas alors que les ORMs restent hégémoniques peut sembler risqué : nous avons besoin d’experts, et on en trouvera plus facilement sur JPA que sur jOOQ. Mais ce serait passer à côté de l’intérêt principal de jOOQ : ce dont vous avez besoin, ce n’est pas d’une expertise sur une nouvelle lib, mais bien de savoir faire du SQL. Tout simplement.



