

Ça fait des décennies qu’on construit nos applications autour d’un ORM. Dans les faits, c’est bien souvent un point de douleur dans nos codes legacy. Alors en quoi l’ORM mène-t-il au legacy ? Et comment un retour au SQL, en utilisant la lib jOOQ, peut-il nous aider à assainir la situation ? C’est ce que nous allons essayer de voir dans cette série de 2 articles.
Mon ORM, c’est du legacy ?
Un ORM (Object-Relational Mapping), c’est une représentation de votre base de données sous forme d’objets, manipulable directement dans votre code. Dans cet article, nous nous limiterons à cette définition stricte, bien qu’en pratique les implémentations existantes aient évolué pour intégrer des fonctionnalités (native queries, query builders, etc.) qui sortent de ce cadre.
Une table n’est pas une classe, et réciproquement. C’est la base de ce qu’on appelle l’object–relational impedance mismatch. Ce qui peut apparaître à première vue comme un simple mapping s’accompagne en réalité de nombreuses problématiques : relations bidirectionnelles, utilisation de la mémoire, nombre de requêtes… Les ORMs tels que JPA apportent des solutions à ces problèmes, mais la complexité induite n’est pas négligeable, ce qui peut amener à une situation de legacy.
Le code legacy, c’est un code sur lequel on a perdu la maîtrise : l’existant rend les évolutions extrêmement complexes, et toute modification a de fortes probabilités d’aboutir à des régressions. En cela, on peut considérer que la complexité des ORMs est un facteur qui amène un code à devenir legacy.
Les chapitres suivants visent à montrer comment cela se manifeste concrètement, dans le cadre d’une application utilisant JPA. Pour cela, ils présentent des exemples basés sur un modèle de données simple, défini pour un atelier d’introduction à jOOQ (disponible dans ce dépôt de code) :
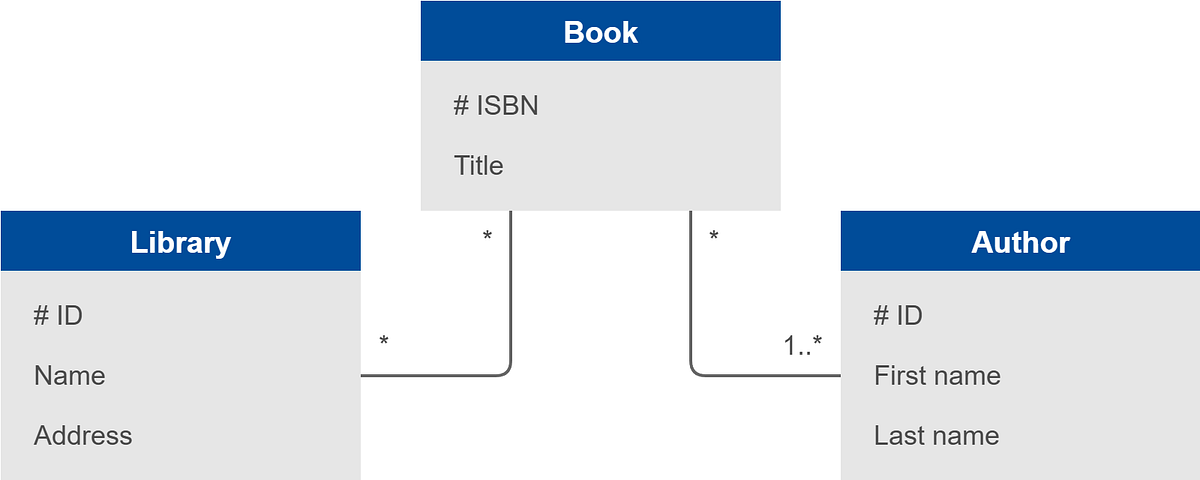
L’enfer des annotations
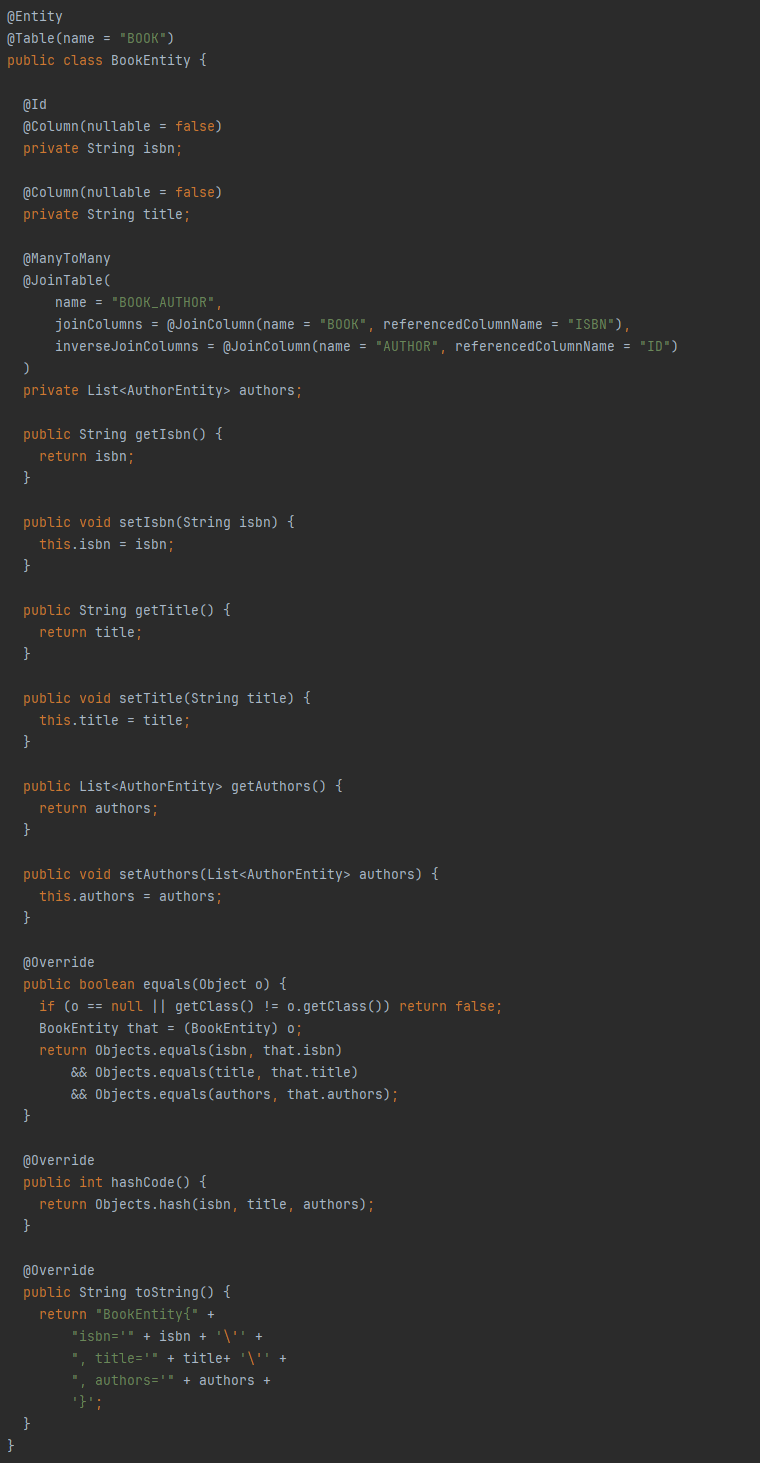
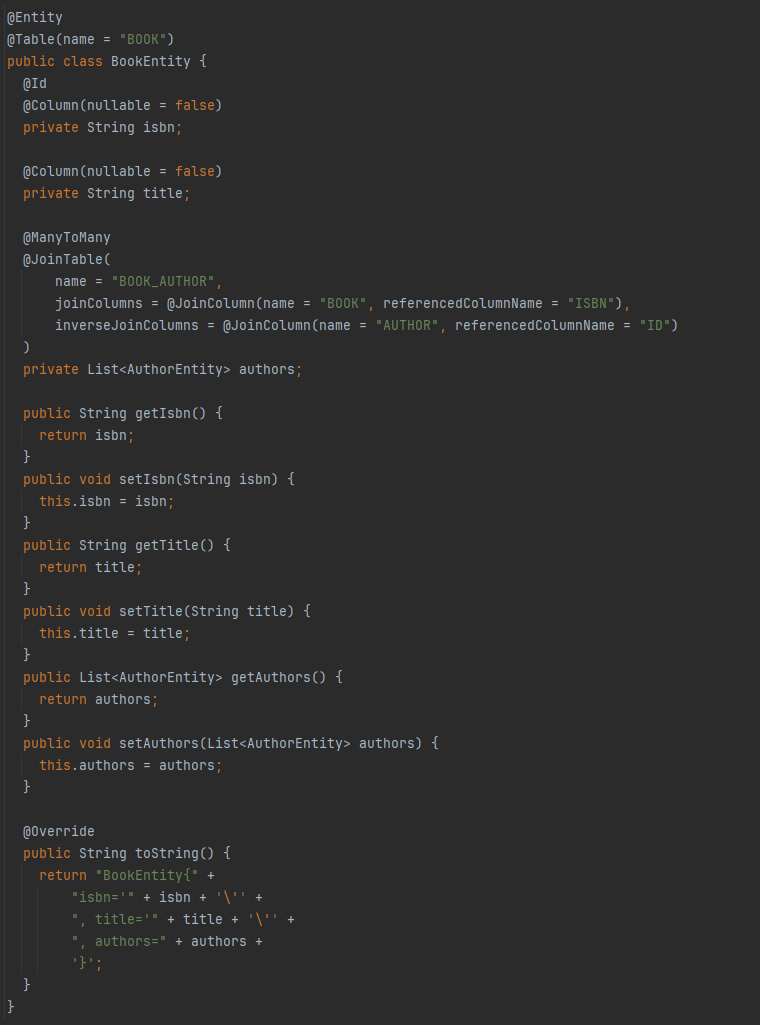
JPA se base sur un système d’annotations pour définir le mapping d’entités avec les tables de votre base de données. Les annotations, c’est très clair tant qu’on reste dans les cas simples. Cependant, même pour un cas aussi commun qu’une relation N-N, la complexité grimpe en flèche :
![@Entity
@Table(name = "BOOK")
public class BookEntity {
@ManyToMany
@JoinTable(
name = "BOOK_AUTHOR",
joinColumns = @JoinColumn(name = "BOOK", referencedColumnName = "ISBN"),
inverseJoinColumns = @JoinColumn(name = "AUTHOR", referencedColumnName = "ID")
)
private List<AuthorEntity> authors;
[...]
}
@Entity
@Table(name = "AUTHOR")
public class AuthorEntity {
@ManyToMany(fetch = LAZY, cascade = ALL, mappedBy = "authors")
private List<BookEntity> publishedBooks = null;
[...]
}](https://shodo.io/wp-content/uploads/2025/11/jooq_1-1.png)
Pour une “simple” jointure dans le cadre d’une relation N-N, on constate qu’on a besoin de 5 annotations avec une dizaine de champs. Chacun de ces champs est susceptible d’être source d’erreur, d’oubli, d’incohérence… Bref, de bugs.
La contamination du modèle objet
JPA impose des contraintes sur la manière de définir les entités pour que les annotations soient bien prises en compte. Ces contraintes constituent une complexité accidentelle qui vient potentiellement contaminer notre code métier.
Par exemple, pour la définition d’un livre dans le modèle, voici ce que nous voudrions définir sans les contraintes de JPA :

Ce que nous définissons effectivement pour JPA s’avère bien plus verbeux :
Les problèmes du one-size-fits-all
Vous avez des cas d’usage avec des besoins différents ? Peu importe, l’ORM se base sur un modèle unique, qui reflète celui de la base de données. Dans notre exemple, si vous chargez une bibliothèque, vous chargerez nécessairement son adresse, même dans des cas où vous ne l’utilisez pas. Bien sûr, dans certains cas, il est possible d’utiliser du lazy loading : on attend que le champ concerné soit utilisé pour le charger. Mais cela s’accompagne d’autres problèmes…
Supposons une méthode qui utilise un champ en lazy loading. Par exemple, la méthode toString de AuthorEntity qui utilise le champ publishedBooks :
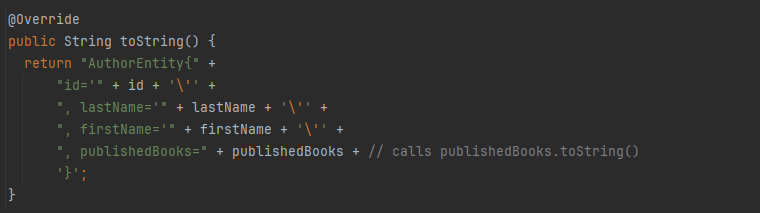
Si on l’appelle après la fermeture de la transaction dans laquelle a été chargée l’instance, cela aboutira à une Lazy Initialization Exception.

Plus grave : même en l’appelant dans le cadre de la transaction, étant donné que la méthode toString de BookEntity utilise le champ authors, cela aboutira à une boucle infinie. Ce genre de dépendance cyclique est un problème de conception typique de la volonté de définir un modèle unique pour des besoins disparates.
C’est pour la magie
Une bonne abstraction expose ce qui est pertinent dans mon contexte et cache ce qui ne l’est pas. Ça “marche”, c’est magique, pas besoin d’aller voir ce qu’il y a derrière. Le problème de l’abstraction proposée par les ORMs, c’est que ce qu’elle vise à cacher, c’est le SQL : savez-vous quelles requêtes SQL sont exécutées par votre code ? Ou même combien, dans le cas où vous utilisez du lazy loading ?
C’est d’autant plus difficile que les requêtes exécutées peuvent varier en fonction du contexte. Même si un accès à des données est testé, il suffit qu’un champ en lazy loading ne soit pas utilisé dans le test pour que toute une partie du comportement ne soit pas testée. Autrement dit, on passe très facilement à côté de bugs.
Une maîtrise généralement trop superficielle
Quand on commence à développer une application avec un ORM, trop souvent, les développeurs n’en ont qu’une maîtrise superficielle. Même si on ne suit pas les bonnes pratiques, même si on ne comprend pas pourquoi, ça fonctionne. Tous les problèmes cités plus haut semblent acceptables. Et ça tient, pendant un temps.
Là où le bât blesse, c’est que les problèmes ne commencent à être vraiment visibles que quand il est déjà trop tard. Quand l’application est devenue trop difficile à maintenir, quand les régressions se multiplient, quand les problèmes de performance ne peuvent plus être ignorés, la complexité du code a déjà explosé. Remédier à cette situation sera excessivement difficile.
L’alternative jOOQ
jOOQ generates Java code from your database and lets you build type-safe SQL queries through its fluent API.
C’est la phrase d’accroche du site officiel de jOOQ. Elle en introduit les 3 principes fondamentaux :
- La fluent API proposée pour accéder à la base de données permet d’écrire simplement un code lisible, dans une syntaxe qui se rapproche autant que possible du SQL.
- Le fait que l’API soit type-safe garantit la validité des requêtes SQL en repérant les erreurs dès la compilation.
- La génération du code garantit la synchronisation avec le schéma de votre base de données.
Exemple de code
Afin d’observer l’impact concret de jOOQ sur le code, intéressons-nous à 2 implémentations d’une même fonctionnalité, avec JPA puis avec jOOQ.
Exemple avec Spring Data JPA
L’exemple suivant utilise JPA avec une couche Spring Data, qui permet d’avoir un code moins verbeux qu’une intégration directe de JPA. Tout comme avec JPA, vous définissez un mapping entre des objets et votre base de données à l’aide d’annotations. Spring Data permet de définir une interface (ici BookRepository) avec les opérations les plus communes disponibles de base et la possibilité d’ajouter des requêtes en se basant sur des conventions de nommage.


Exemple avec jOOQ
Pour aboutir au même résultat avec jOOQ, on observe que, une fois la génération à partir de la base de données correctement configurée, le code est relativement simple. Il suffit d’utiliser une instance de DSLContext et de se baser sur le code généré (AUTHOR, AUTHOR.ID, etc.).
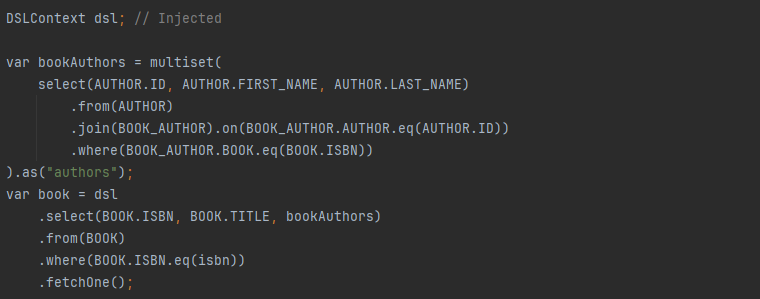
La requête elle-même peut sembler un peu plus complexe qu’avec Spring Data, mais elle ne nécessite pas de définir une entité JPA.
Et le plus important, c’est que la syntaxe est quasiment identique au SQL. Pour référence, la requête SQL qui sera exécutée :
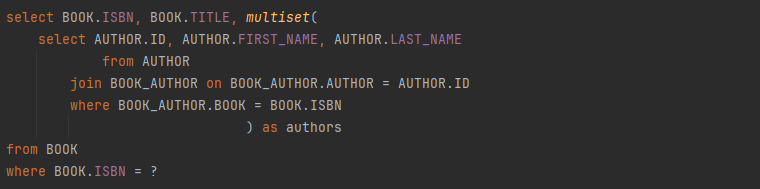
On constate d’ailleurs qu’il s’agit d’une requête unique, alors que le code JPA donnait lieu à N+1 requêtes (cf. Eager or lazy loading).
Comparatif
Cet exemple de code permet de noter plusieurs points.
Du SQL explicite
Avec jOOQ, les requêtes doivent être écrites explicitement.
Ce qui peut sembler plus verbeux est en réalité une bonne nouvelle pour la maintenabilité de votre code : pas besoin de deviner ce que fait le framework, le SQL est disponible directement sous vos yeux.
Ceci nous permettra d’anticiper d’éventuels problèmes de performance, comme ça a pu être le cas pour le problème dans le nombre de requêtes exécutées.
La flexibilité du SQL
La possibilité d’écrire les requêtes sous forme de SQL nous en donne toute la flexibilité : tout ce qui est possible en SQL est possible avec jOOQ, sans besoin de connaître les subtilités d’un framework supplémentaire. C’est ce qui nous a permis de réduire le nombre de requêtes par l’utilisation de l’opérateur multiset.
Il est à noter que certaines fonctionnalités spécifiques à des SGBD ne sont pas nativement supportées par jOOQ, mais il est possible de les intégrer simplement. Par exemple, pour utiliser la fonction unaccent de l’extension PostgreSQL du même nom :

Un code testable
Le fait de devoir écrire chaque requête permet de s’inscrire dans une logique TDD.
Testerchaque requête devient facile, naturel, avec tous les bénéfices qui en découlent, que ce soit avec une base de données en mémoire si vous vous limitez à du SQL standard, ou avec TestContainers si vous utilisez des fonctionnalités spécifiques à un SGBD en particulier.
Moins de code à maintenir
Passer de Spring Data JPA à jOOQ peut sembler plus verbeux : au lieu d’utiliser une interface toute prête, il est nécessaire d’écrire les requêtes SQL, quand bien même elles seraient triviales.
Néanmoins, cette augmentation du nombre de lignes est largement compensée par la disparition des entités JPA. En remplaçant celles-ci par du code généré, la quantité de code à maintenir est globalement moins importante.
Disparition du biais du paradigme objet
L’accès aux données ne passe plus par le paradigme objet mais par des requêtes SQL, dans le paradigme relationnel. Ainsi, nous avons fait disparaître un biais. Toute la complexité introduite spécifiquement par l’ORM, décrite plus tôt, n’a plus de raison d’être. Plus de lazy loading, plus de cache au niveau de la couche d’accès… Chaque requête répond à un besoin, précisément, explicitement et sans ambiguïté.
Nous avons vu dans ce premier article que l’ORM est une source de complexité dans votre code legacy. En le remplaçant, jOOQ rend le code plus expressif, plus explicite. Et c’est en soi un assainissement de votre legacy, dans le sens où votre code est devenu plus facile à maintenir.
Toutefois, la migration est-elle vraiment si simple ? Comment prendre en compte ce changement de paradigme en profondeur pour en tirer pleinement parti ? Rendez-vous dans le second article de cette série pour en savoir plus !



