

Ça vous est arrivé, d’éviter de modifier une fonction, par peur de causer des bugs ? De vous énerver en essayant de comprendre comment fonctionne le code source du projet que vous venez de rejoindre ? D’avoir des sueurs froides en approuvant les quelques modifications de code proposées par votre collègue dans sa Pull Request ?
Si oui, vous avez eu affaire à ce qu’on appelle du code legacy. On parle de legacy (héritage, en anglais) car il s’agit généralement de code qu’on a hérité d’un autre développeur. Le manque de documentation et de tests automatisés fait que les développeurs ont peur de le casser — sans forcément s’en rendre compte — en le modifiant.
Heureusement, le code legacy n’est pas une fatalité. Nous allons voir ensemble quelques techniques de software craft pour reconstruire ce code sans repartir de zéro, afin de retrouver de la confiance et du plaisir à le maintenir.
Je suis développeur web depuis 2006. Actuellement, j’aide une Startup d’État à restructurer le code source d’une application de traitement de données. L’équipe ayant dû prendre quelques raccourcis, elle se retrouve à perdre des heures de travail suite à l’apparition récurrente de bugs. À côté, j’entretiens Openwhyd, une application web musicale que j’avais développé au sein d’une startup entre 2012 et 2015 puis que j’ai open-sourcé en 2016. La plupart des exemples donnés dans cet article viennent de ces deux expériences.

Le legacy n’est pas une fatalité
Trop souvent, lors de discussions entre développeurs, le code legacy est mentionné comme source de dégoût et de dédain. Travailler sur du code legacy est vécu comme une punition. Les auteurs de ce code sont jugés pour leurs choix de technologies devenues désuètes, le manque de clarté et de concision dans le code, ou encore le manque de tests automatisés.
“Si un code legacy est encore maintenu, c’est qu’il a de la valeur.”
Contribuer au développement d’un code source legacy est à priori moins tentant que démarrer un projet tout neuf basé sur des frameworks à la mode. Mais lequel des deux a le plus d’impact, en réalité ? Si un code legacy est encore maintenu, c’est qu’il a de la valeur. S’il n’apportait pas de valeur à son propriétaire, ce dernier s’en serait déjà débarrassé !
La première fois que j’ai été confronté à du code legacy, c’était lors d’un stage. Ma mission était d’extraire une fonctionnalité d’un logiciel dans une bibliothèque dynamique, afin de pouvoir la remplacer par une autre. Le défi était surtout d’y parvenir en l’absence de documentation et des auteurs du code source. Cette expérience m’a appris à définir une stratégie basée sur la formulation d’hypothèses, puis à les vérifier, méthodiquement, une à une. Au début, je trouvais le travail assez difficile et rébarbatif, en comparaison du développement d’un projet logiciel tout neuf. Au final, la réussite de cette mission m’a apporté une satisfaction et une montée en compétence insoupçonnées !
Nous sommes tous coupables d’avoir écrit du code legacy !
Pensez-vous qu’écrire du code legacy soit une décision ? Une chose est sûre: nous en avons tous écrit, car aucun de nous n’est parfait. Un expert en SQL ne sait pas forcément écrire des tests automatisés. Un testeur ne sait pas forcément comment nommer ses variables. Un CTO de startup ne sait pas forcément comment mettre toute son équipe d’accord sur une stack et un outillage commun. Nous sommes tous coupables d’avoir écrit du code legacy, donc nous ne sommes pas en position de juger le code des autres.
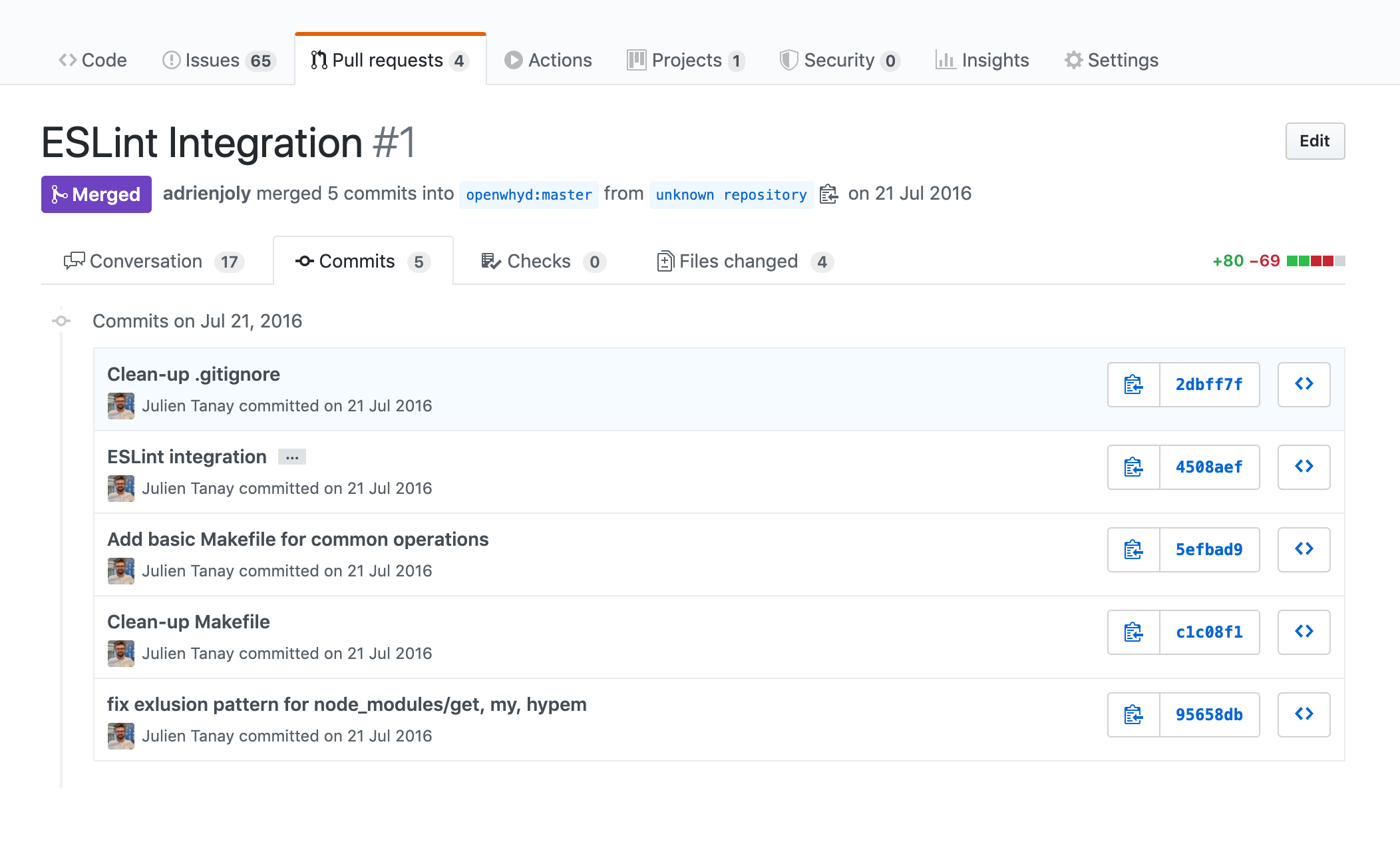
En reprenant le code que j’avais écrit plusieurs années auparavant, j’ai souffert du manque de clarté de mon propre code, du manque de tests automatisés et du manque de maturité dont j’avais fait preuve dans la conception de certaines fonctionnalités devenues inmaintenables. En l’open-sourçant, j’ai compris que savoir maintenir mon propre code ne suffisait pas. Les contributeurs potentiels ont une connaissance quasi-nulle sur le produit et sa conception et ni eux ni moi ne voulons passer des heures à discuter avant d’intégrer un correctif. Pour preuve: le premier Pull Request que j’ai reçu n’était ni un correctif, ni une fonctionnalité. C’était l’ajout d’une configuration de linter et un Makefile ! Un signe que la définition de normes explicites et l’automatisation des tâches de base sont des pré-requis à la collaboration sur un code source.
1. Installation, documentation et alignement sur la méthodologie avec l’équipe
Fort de cette expérience, c’était à mon tour de prendre la casquette de “contributeur”. L’équipe de la Startup d’État “Signaux Faibles” cherchait ce genre de profil et compétences; c’est pourquoi j’ai intégré le projet. J’ai commencé par observer ce qui était déjà en place: plusieurs dépôts git, de la documentation et quelques tests automatisés.
Pour mieux comprendre leur manière de développer, leurs conventions de codage, nous avons planifié ensemble des sessions régulières de pair programming. Pendant ces sessions, nous réparons des tests automatisés, nous explorons les parties importantes du code source et je me familiarise avec leur stack technologique. Chaque session se termine sur la soumission d’un pull request que nous relisons ensemble, puis sur une rétrospective pour partager notre ressenti sur la session et nos souhaits pour les prochaines. On fait le maximum pour garder des traces écrites des choix qui ont été faits, pendant ou avant ces sessions, pour que cela serve de documentation.
L’idéal est de commencer par travailler sur un chantier de taille et de risques réduits.
L’idéal est de commencer par travailler sur un chantier de taille et de risques réduits. Sur un composant plutôt isolé du reste de l’application, afin d’éviter au maximum les effets secondaires. En effet, il sera plus facile et moins risqué de refondre le reste une fois que ces composants seront plus solides. Et de se servir de ce premier chantier comme d’un modèle pour les prochains, qui seront à priori plus complexes.
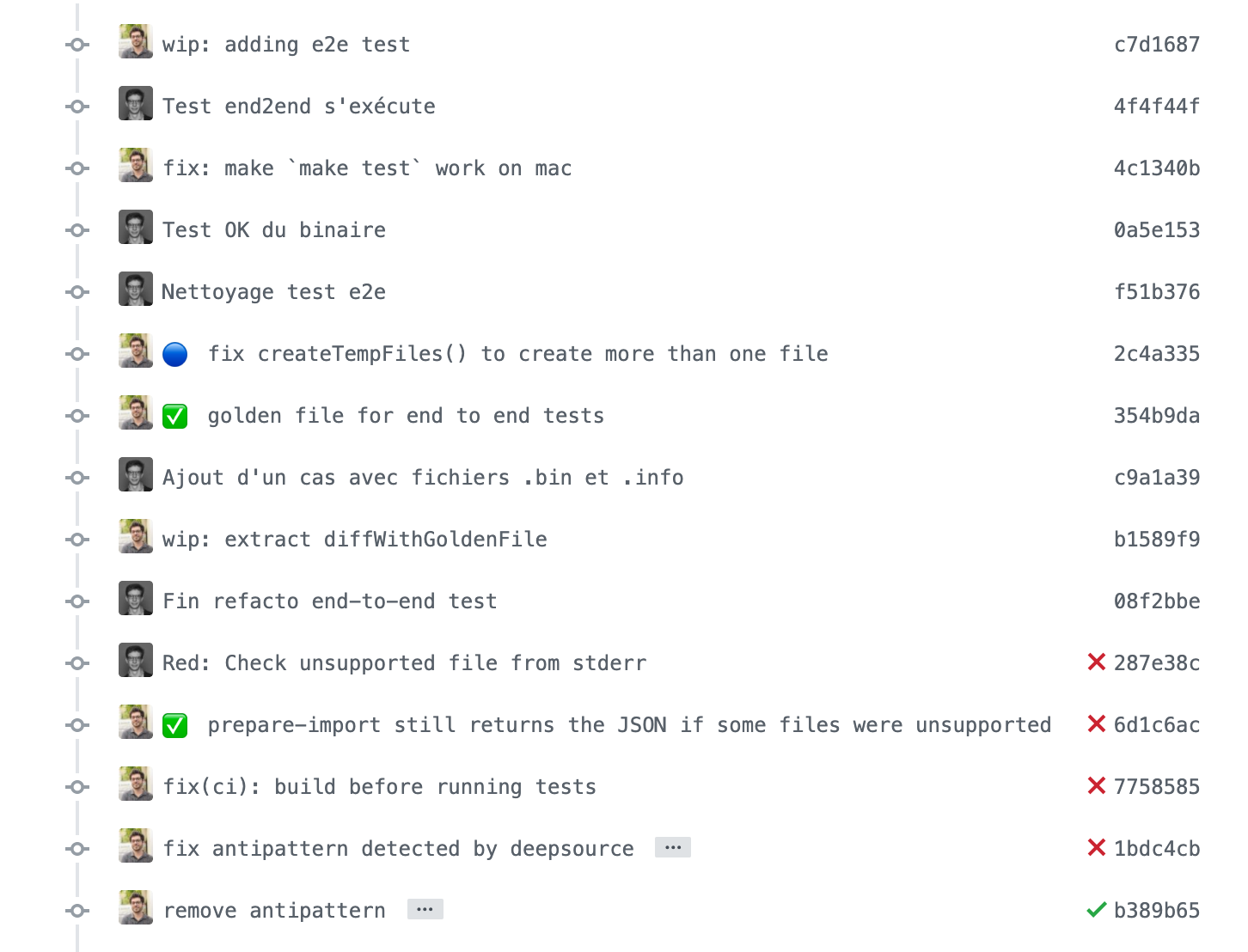
Nous avons alors décidé de commencer par écrire un script visant à automatiser une procédure manuelle gourmande en temps et en attention. En effet, le fait que ce script n’ait pas d’impact direct sur le reste du code implique un risque réduit en cas de raté. Et son périmètre réduit en fait un projet réalisable en peu de temps, idéal pour nos premiers pas en pair programming, effectués en TDD. Ensuite, nous focaliserons sur la refonte d’un ensemble de fichiers JavaScript employés dans une opération map-reduce exécutée par le serveur de données MongoDB.
Au fur et à mesure de mes discussions avec l’équipe et de l’usage de leurs logiciels, je prends des notes de ce que je comprends sur le métier, l’utilité et le fonctionnement de chaque dépôt, les procédures courantes… Puis je demande systématiquement une validation de ces notes, que ce soit pour les intégrer dans le dépôt de documentation du projet, pour ajouter des commentaires dans le code source ou pour me constituer un glossaire.
Par exemple, j’aime profiter de mon regard neuf sur un code source pour l’installer sur ma machine en suivant les instructions fournies dans sa documentation. Puis je propose de les compléter, si besoin. Chez Signaux Faibles, j’ai été un cran plus loin: j’ai rédigé une procédure d’installation dans laquelle chaque service sous-jacent est lancé depuis un conteneur Docker. Cela permet de rendre leur installation plus automatique et portable. Et d’éviter d’installer plusieurs versions de chaque service sur ma machine, accessoirement. 😉
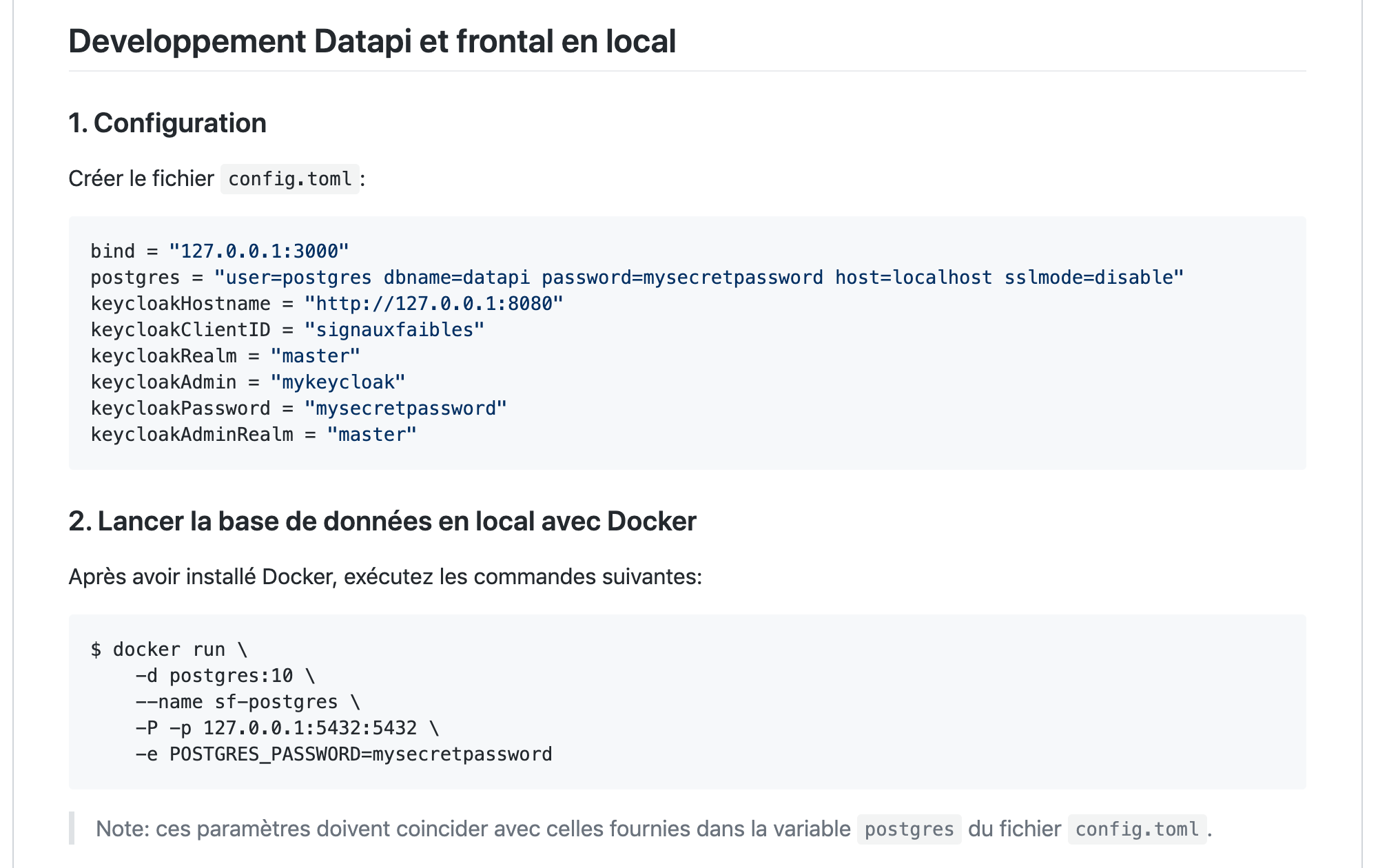
Suite à ces premières itérations, j’ai une meilleure vision du projet, de la manière de travailler de l’équipe et je commence à voir des opportunités d’améliorations.
2. Sécuriser son développement grâce aux tests et outils de suivi
À ce stade, j’ai compris les enjeux du projet et de son équipe, au moins sur la partie technique. J’ai une vision d’ensemble sur le code source existant, sa documentation, et une cartographie des périmètres qui bénéficieraient le plus d’être retravaillés en premier. Cela ne veut pas dire que nous sommes prêts à nous lancer dans la refonte !
Tests en Intégration Continue
Sachant qu’une refonte peut échouer, causer des anomalies qui peuvent revenir cher aux personnes qui comptent sur le bon fonctionnement du logiciel, il est important de prendre des précautions. Pour garantir que le logiciel continue de fonctionner comme prévu, il faut le tester tout au long de la refonte. Pour cela, nous devons écrire des tests de plusieurs niveaux de granularité:
- des tests unitaires pour chaque composant;
- des tests d’intégration avec tous les composants liés;
- et des tests fonctionnels (aussi appelés “de bout en bout”) couvrant le fonctionnement du système dans son ensemble.
Pour réduire le risque d’oubli, ces tests doivent pouvoir s’exécuter de manière automatique et de manière régulière.
Pour réduire le risque d’oubli, ces tests doivent pouvoir s’exécuter de manière automatique et de manière régulière. La manière la plus courante consiste à mettre en place une chaîne d’Intégration Continue (CI) qui exécutera ces tests systématiquement, à chaque fois que des modifications de code seront proposées par l’équipe dans le dépôt du projet.
Le code source de Signaux Faibles étant hébergé dans des dépôts publics sur GitHub, nous pouvons bénéficier gratuitement de diverses solutions de CI. J’ai recommandé l’usage de GitHub Actions, pour son intégration dans GitHub (outil déjà utilisé par l’équipe), sa simplicité de mise en oeuvre, et ses fonctionnalités bien suffisantes pour nos besoins. Nous l’avons configuré de manière à ce que les tests soient exécutés à chaque fois qu’un Pull Request est soumis, et à chaque fois qu’un commit y est ajouté.
Cela nous permet d’itérer avec confiance sur nos tâches de développement, en comptant sur le bon passage de nos tests comme filet de sécurité. Si les tests ne passent pas, cela veut dire que le code que nous avons suggéré ne fonctionne pas comme il devrait, et qu’il faut donc le modifier à nouveau. On ne fusionne les modifications qu’une fois que les tests sont au vert, et qu’un autre équipier les a lu et validé. Le Peer review est important pour intercepter toute erreur qui aurait pu passer entre les mailles du filet des tests, mais aussi pour progresser et aligner nos pratiques de codage au sein de l’équipe.
Suivi de couverture des tests
Comment réduire le risque qu’un bug passe entre les mailles du filet de nos tests automatisés ? Il est très difficile d’apporter une réponse complète et garantie à cette question, mais nous pouvons au moins suivre quelles parties du code source ne sont pas (encore) couvertes par des tests. L’important est d’assurer que la couverture ne baisse pas, lorsqu’on intègre des changements dans le code source.
L’important est d’assurer que la couverture ne baisse pas, lorsqu’on intègre des changements dans le code source
La couverture est mesurée par l’outil d’exécution des tests. Par exemple, dans le monde JavaScript/TypeScript, Istanbul est couramment employé. À la fin de l’exécution des tests, l’outil génère un fichier qui rapporte le pourcentage de code qui a été exécuté à la demande des tests, dans chaque fichier du code source.
Pour pouvoir suivre l’évolution de cette couverture, il est possible de générer ce rapport à chaque exécution des tests dans l’environnement de CI (et donc, à chaque fois qu’une modification est proposée dans le code source), puis de le transmettre à un service qui nous avertira en cas de baisse.
Nous testons actuellement le service Codacy à cette fin.
Un taux de couverture de 100% ne garantit pas un système exempt de toute anomalie
Je tiens à préciser qu’atteindre un taux de couverture de 100% ne garantit en aucun cas que votre système est exempt de toute anomalie, même si vos tests sont impeccables. En effet, il est impossible de simuler toutes les combinaisons de cas que votre système pourrait être amené à traiter à un moment donné.
Suivi de qualité
Comment l’équipe peut-elle mesurer les améliorations apportées par la refonte ? Il est possible de suivre certains indicateurs. Par exemple, l’évolution: du nombre de fonctionnalités livrées par semaine, du nombre de bugs rencontrés par semaine, du temps passé sur du déboggage, du niveau de satisfaction exprimé par les développeurs, etc…
Au delà de ces indicateurs, il est également possible de suivre des indices basés sur l’analyse du code source lui-même: complexité cyclomatique, mise à jour des dépendances, respect de bonnes pratiques de conception, etc…
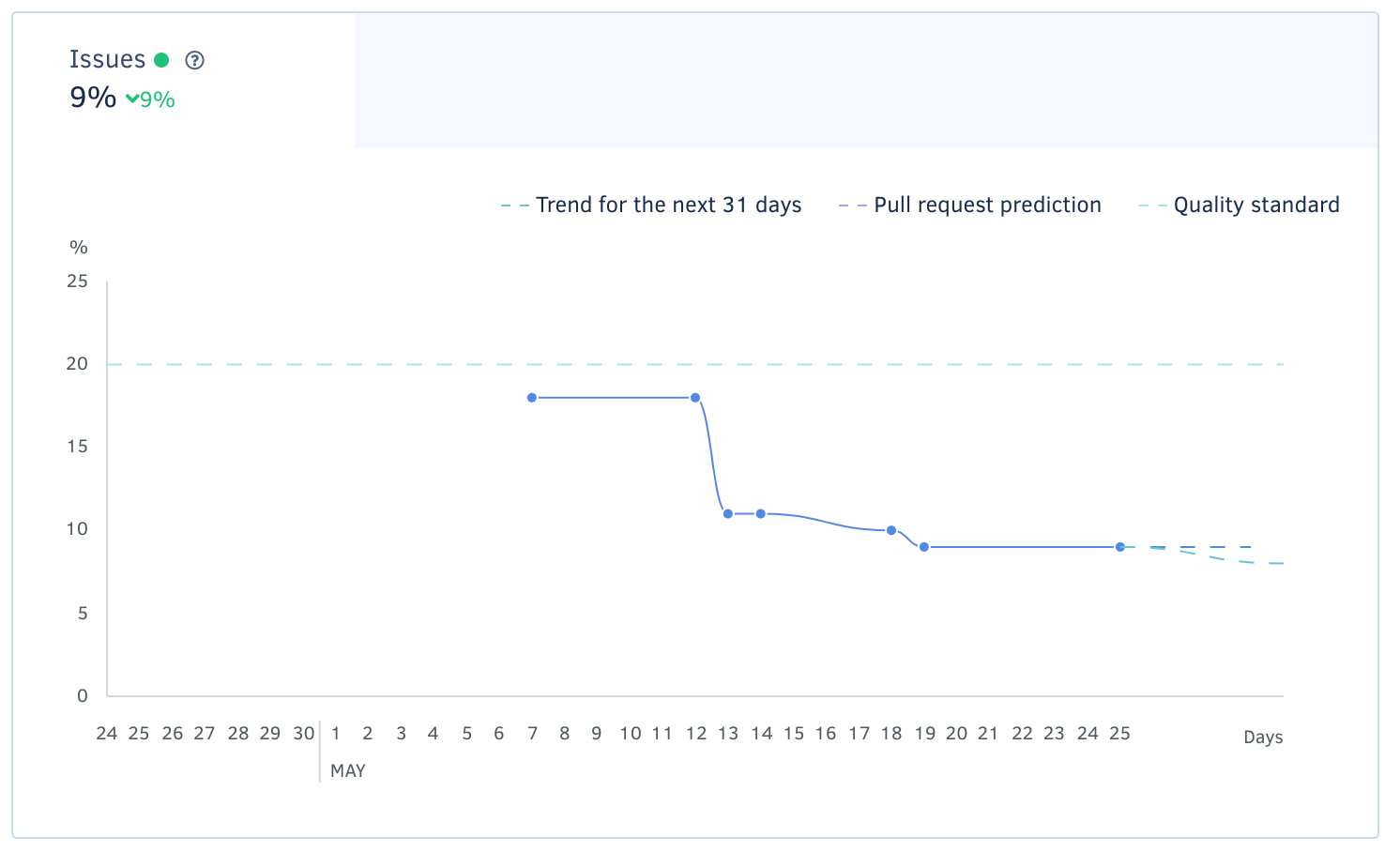
Mais aussi, et surtout, il est relativement simple de mesurer et corriger automatiquement (dans certains cas) le respect de conventions de codage choisies par l’équipe, par l’usage d’un linter et la définition d’une configuration pour celui-ci. Par exemple, le linter vérifiera que les fichiers de code respectent les préférences de l’équipe en termes d’indentation (ex: tabulations ou espaces ? combien ?), d’usage ou non de points-virgules après chaque instruction, de manières d’utiliser la casse dans les noms de variables et de fonctions, et j’en passe…
Certains langages de programmation (ex: le langage Go) ont leurs propres conventions et leur propre linter. D’autres, comme JavaScript et TypeScript, sont plus agnostiques. Le choix des règles à respecter reviendra donc à l’équipe. J’ai suggéré puis mis en place ESLint pour assurer le suivi de ces règles dans les fichiers JavaScript et TypeScript de Signaux Faibles.
Similairement à la couverture des tests, ces indicateurs peuvent être suivis et surveillés par des outils tiers, exécutés depuis notre environnement de CI. Nous employons également Codacy à cette fin.
3. Itérations de refonte
Comme je l’expliquais plus haut, il est plus sûr de refondre le code source de manière progressive, en commençant par les composants ayant le moins de risque d’impacter les composants les plus critiques du système.
Au delà du risque, il faut aussi prendre en compte l’impact de l’amélioration des composants
En revanche, au delà des risques, il est important de prendre en compte l’impact qu’apporterait l’amélioration de chacun des composants considérés. L’idéal est de pouvoir commencer par refondre un composant relativement isolé des autres mais dont l’usage et/ou la maintenance sont actuellement très coûteux pour les personnes concernées.
La nature de cet impact aidera à décider de la stratégie de refonte à suivre.
Les tests comme gardiens fonctionnels
Quelle que soit cette stratégie, il est primordial de disposer d’un minimum de tests automatisés, pour garantir que nos modifications ne causeront pas d’anomalies fonctionnelles, tout au long de notre refonte.
Idéalement, vous devriez disposer:
- de tests fonctionnels (de bout en bout) pour les fonctionnalités du système qui pourraient être impactées par la refonte;
- de tests unitaires pour les fonctions que vous (ré)écrivez;
- et, si nécessaire, de tests d’intégration employant également les composants avec lesquelles le composant en refont interagit.
Chez Signaux Faibles, l’équipe avait déjà produit quelques tests unitaires et d’intégration consistant à comparer les données résultantes de traitements (implémentés par des fonctions) avec un résultat de référence. C’est ce qu’on appelle un golden master. À défaut d’être explicite et précise quant aux attentes de chaque test, cette méthode est un bon début pour mesurer les impacts potentiels de nos modifications sur le fonctionnement du système. Nous avons donc commencé par référencer ces tests, les réparer quand nécessaire, et rendre plus aisée leur exécution.
Dès lors, nous avons pu intégrer l’exécution de tous les tests existants dans la chaîne d’intégration continue. Cela nous a permis de vérifier que chaque modification suivante ne causait pas d’anomalie, en tout cas sur les cas d’usages couverts par ces tests.
Exemple: Migration vers TypeScript en TDD et pair coding
Sur cette base, nous avons décidé de procéder à une refonte progressive, fonction par fonction.
La refonte de chaque fonction consiste:
- à expliciter les types de données qu’elle manipule (en entrée et sortie, par l’usage du langage TypeScript);
- à écrire des tests unitaires dont les intitulés serviront de documentation fonctionnelle;
- puis à refactoriser la fonction de manière à la rendre plus lisible, robuste et plus facile à tester.
Pour éviter de nous éparpiller en tentant de résoudre trop de problèmes à la fois, nous appliquons la méthode TDD (Test-Driven Development). À la différence que nous ne passons pas par l’étape “rouge” — consistant à écrire un test qui ne passe pas — dans les cas où la fonctionnalité testée est déjà correctement implémentée.
Pour avancer avec confiance, nous travaillons principalement en pair programming: un de nous dicte à l’autre les modifications qu’il souhaite apporter, puis on inverse les rôles toutes les 10 minutes. Cette manière de travailler nous permet aussi de nous aligner de manière explicite et immédiate sur les préférences et choix techniques. Notamment: la manière de nommer les fonctions et variables.
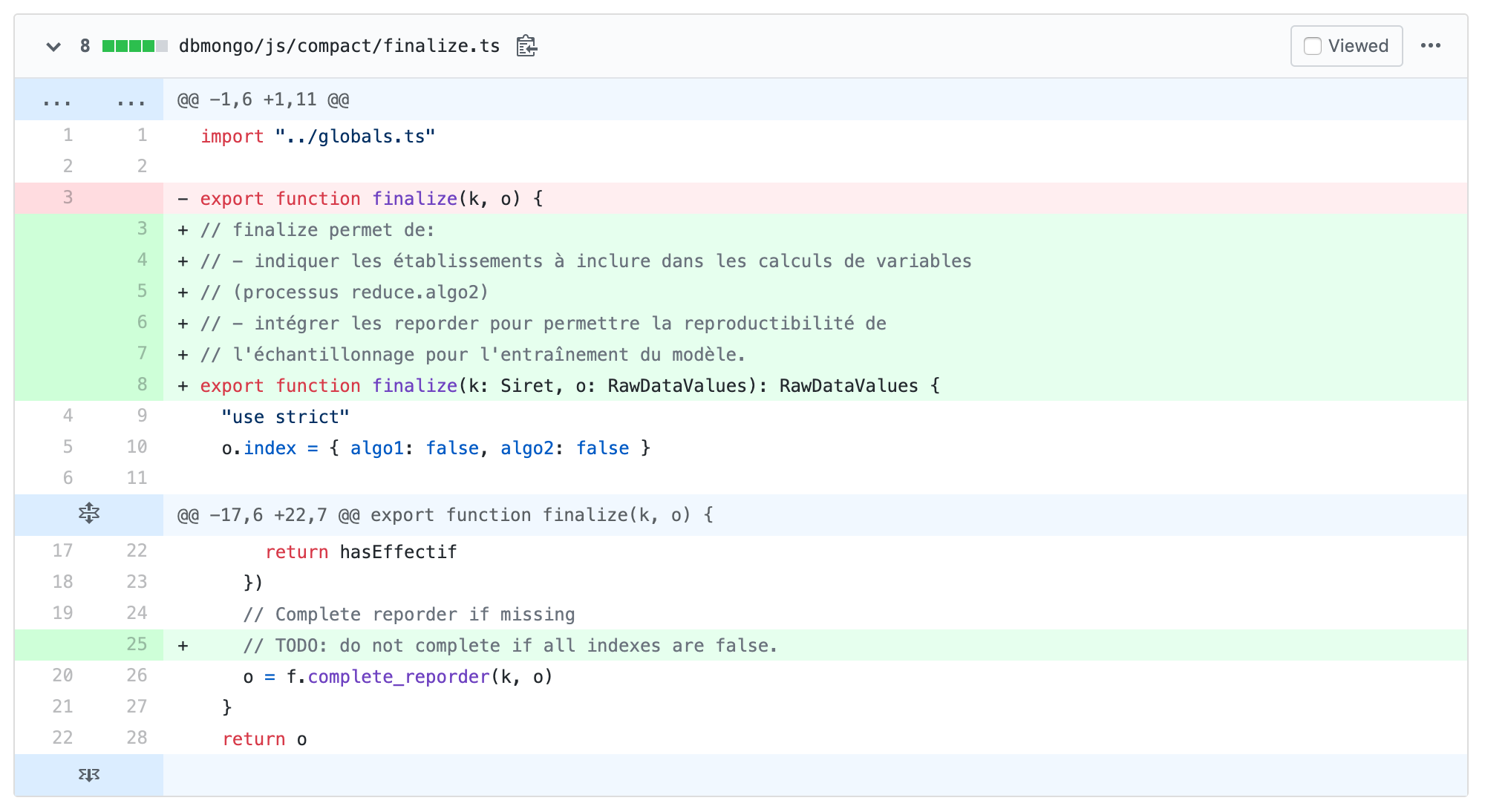
À la fin de chaque séance (de 2h30, généralement), nous soumettons un Pull Request, prenons le temps de décrire les changements apportées, d’observer les résultats de la chaîne d’intégration continue (notamment les indicateurs de couverture et de qualité fournis par Codacy) puis de fusionner ces modifications dans la branche principale du dépôt, quand ceux-ci sont complets et fonctionnels.
La stratégie que nous avons décidé de suivre est adaptée aux attentes de Signaux Faibles sur le périmètre en question: prévenir les erreurs de manipulation de données lors de l’exécution de la chaîne de calcul de données, sachant que celle-ci dure plusieurs heures. Elle n’est pas forcément un modèle à choisir pour votre propre projet de refonte, mais permet de donner un exemple concret, et de partager le raisonnement que nous avons suivi pour prendre ces décisions.
Le legacy, un défi passionnant !
J’espère être parvenu à vous convaincre que le “code legacy” n’est pas une fatalité, et que refondre un code source legacy peut être un défi technique tout aussi passionnant et gratifiant (si ce n’est plus) que celui de travailler sur un code source neuf.
J’insiste sur le fait que les techniques et outils mentionnés ici ont été choisies en fonction des caractéristiques de l’existant, des contraintes et préférences de l’équipe (en comptant les miennes), et de nos connaissances à l’instant T. Je ne préconise en aucun cas de suivre cet exemple à la lettre. Au contraire, j’espère que vous retiendrez de cet article le raisonnement que nous avons suivi pour adopter une façon de faire.
Et vous, avez-vous déjà travaillé sur la refonte d’un code legacy ? Au plaisir de lire votre histoire !
Je tiens à remercier chaleureusement mon excellent binôme, Pierre Camilleri, et toute l’équipe de Signaux Faibles pour le soutien et la confiance qu’ils m’accordent pendant cette mission. Merci également à Fabien Maury, Elodie Quezel et Laury Maurice pour m’avoir aidé à rédiger et améliorer cet article.



